体绘制剪裁¶
项目源码
参考案例
1 介绍¶
_业务层面
体绘制中的剪裁通常可以归纳为两类常见需求:
- 基于三维空间中的包围盒或裁剪平面,直接调整体数据的可见范围,从空间结构上限制显示区域;
- 基于当前视角,在屏幕上绘制任意闭合多边形,将其作为掩膜对体数据进行裁剪,实现类似“手术刀”式的交互效果。
前者属于空间结构限制,后者属于视角驱动的交互式裁剪。
_实现层面
从实现路径来看,无论是哪种业务需求,技术上都可以分为两类方案:
- 数据级剪裁:直接修改体数据本身,将不需要的体素值改为空气值或零值,从源数据层面移除;
- 渲染级剪裁:在渲染阶段通过 shader 条件判断决定是否参与采样或累积,不改变原始数据,只影响最终显示结果。
数据级方案改变数据本体,渲染级方案只改变显示逻辑。
_性能层面
从性能角度分析,尤其是基于屏幕 mask 的剪裁,本质上涉及对体素空间的全量遍历,其理论复杂度为 O(N³)。当数据规模较大时,CPU 侧逐体素修改并回写数据的开销会非常明显。
因此在工程实践中,更推荐:
- 将计算放在 GPU 上并行执行;
- 或者直接在体渲染阶段通过 shader 做实时条件判断。
这样可以避免频繁修改体数据带来的额外内存与计算成本,同时保持更好的交互性能。
2 平面裁剪¶
其实现思路是在体渲染的光线步进过程中,将裁剪平面方程传入 shader,对每一个采样点进行平面测试,如果采样点位于被裁掉的一侧就直接跳过或终止当前光线积分,从而在不修改原始体数据的前提下,通过 GPU 上的实时判断实现裁剪效果。
vtkAbstractMapper 内部已经封装好了对应实现,只需要通过 SetClippingPlanes 传入平面即可。比如将 vtkBoxWidget2 的包围平面传入:
class vtkBoxWidgetCallback : public vtkCommand
{
public:
static vtkBoxWidgetCallback * New()
{
return new vtkBoxWidgetCallback;
}
void Execute(vtkObject * caller, unsigned long, void *) override
{
vtkBoxWidget2 * boxWidget = reinterpret_cast<vtkBoxWidget2 *>(caller);
vtkBoxRepresentation * rep = reinterpret_cast<vtkBoxRepresentation *>(boxWidget->GetRepresentation());
vtkNew<vtkPlanes> planes;
rep->GetPlanes(planes);
rep->SetInsideOut(1);
m_Mapper->SetClippingPlanes(planes);
}
vtkBoxWidgetCallback()
{
}
vtkAbstractVolumeMapper * m_Mapper = nullptr;
};
3 自定义剪裁¶
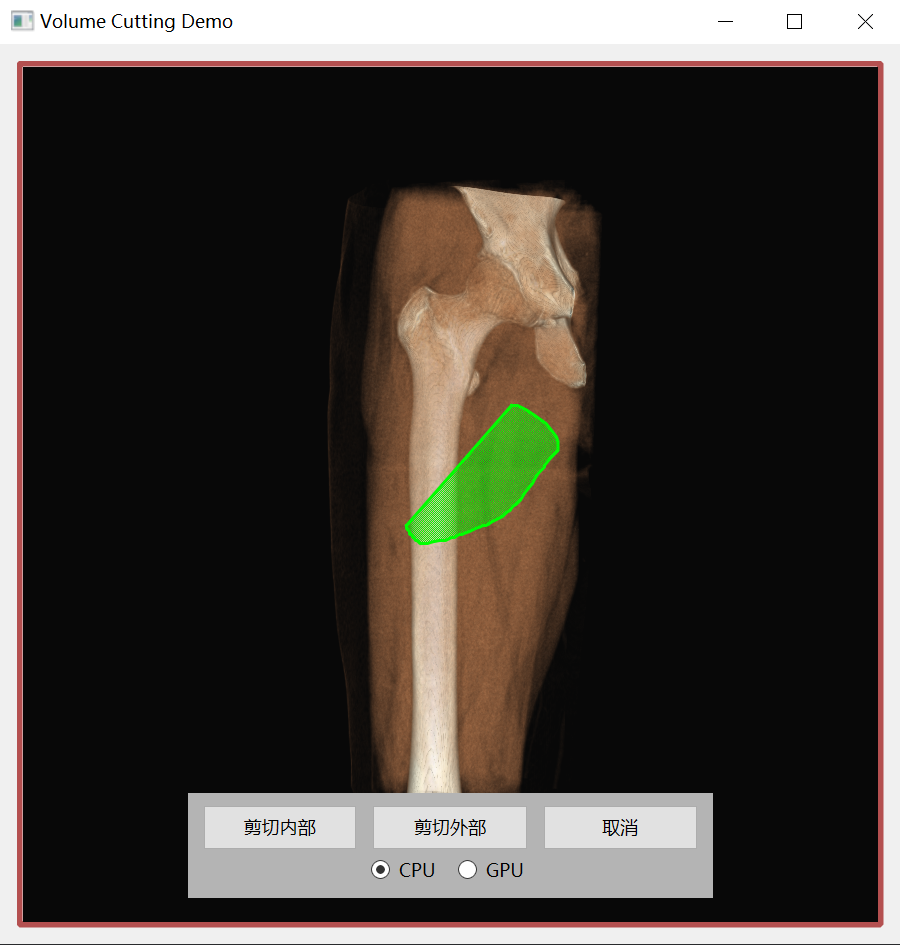
把三维体数据中的每一个体素通过当前相机的视图投影矩阵变换到屏幕空间,然后根据屏幕上绘制的多边形或生成的二值 mask 来决定这个体素是否需要被保留或置为空气值。
本质上是一次 3D 到 2D 的映射再反向作用回 3D 数据的过程,和基于空间包围盒的裁剪不同,它完全基于当前视角,因此可以实现类似手术刀一样的任意形状屏幕剪裁效果。
3.1 获取屏幕mask¶
绑定 QEvent::MouseMove 的事件,依次记录鼠标轨迹点。使用 QPolygonF 完整绘制 mask 。
3.2 CPU¶
CPU 版本就是最直接的实现方式,先根据当前相机计算出 MVP 矩阵,然后三重循环遍历所有体素坐标,把每个体素从 world 空间投影到屏幕空间,得到对应的 UV,再去 mask 图中查询是否命中。如果命中并满足裁剪条件,就把该体素值改成空气值。逻辑清晰、调试方便,但本质是对全部体素做一次遍历,数据量大时性能压力比较明显,更适合验证算法或数据规模不大的场景。
void VolumeCutter::Cut(vtkImageData * volume, vtkRenderer * ren,
const QImage & mask, bool cutInside,
vtkPlanes * clipPlanes, int airValue)
{
if (!volume || !ren) {
return;
}
QElapsedTimer timer;
timer.start();
int dims[3];
double origin[3], spacing[3];
volume->GetDimensions(dims);
volume->GetOrigin(origin);
volume->GetSpacing(spacing);
vtkCamera * cam = ren->GetActiveCamera();
vtkNew<vtkMatrix4x4> view;
view->DeepCopy(cam->GetViewTransformMatrix());
double clippingRange[2];
cam->GetClippingRange(clippingRange);
vtkNew<vtkMatrix4x4> proj;
proj->DeepCopy(cam->GetProjectionTransformMatrix(ren->GetTiledAspectRatio(), clippingRange[0], clippingRange[1]));
vtkNew<vtkMatrix4x4> mvp;
vtkMatrix4x4::Multiply4x4(proj, view, mvp);
QImage grayMask = mask.convertToFormat(QImage::Format_Grayscale8);
const int maskW = grayMask.width();
const int maskH = grayMask.height();
const uchar * maskBits = grayMask.constBits();
const int maskBpl = grayMask.bytesPerLine();
int * scalars = static_cast<int *>(volume->GetPointData()->GetScalars()->GetVoidPointer(0));
// 按 Z 切片并行处理
QVector<int> slices(dims[2]);
std::iota(slices.begin(), slices.end(), 0);
QtConcurrent::blockingMap(slices, [&](int z) {
double wz = origin[2] + z * spacing[2];
for (int y = 0; y < dims[1]; ++y) {
double wy = origin[1] + y * spacing[1];
for (int x = 0; x < dims[0]; ++x) {
double wx = origin[0] + x * spacing[0];
double pt[3] = { wx, wy, wz };
if (clipPlanes->EvaluateFunction(pt) > 0.0) {
continue;
}
double clipX = mvp->GetElement(0, 0) * wx + mvp->GetElement(0, 1) * wy
+ mvp->GetElement(0, 2) * wz + mvp->GetElement(0, 3);
double clipY = mvp->GetElement(1, 0) * wx + mvp->GetElement(1, 1) * wy
+ mvp->GetElement(1, 2) * wz + mvp->GetElement(1, 3);
double clipW = mvp->GetElement(3, 0) * wx + mvp->GetElement(3, 1) * wy
+ mvp->GetElement(3, 2) * wz + mvp->GetElement(3, 3);
if (qFuzzyIsNull(clipW)) {
continue;
}
double ndcX = clipX / clipW;
double ndcY = clipY / clipW;
// NDC -> 屏幕 UV [0,1]
double u = ndcX * 0.5 + 0.5;
double v = ndcY * 0.5 + 0.5;
if (u < 0.0 || u > 1.0 || v < 0.0 || v > 1.0) {
if (!cutInside) {
vtkIdType idx = z * (vtkIdType)dims[1] * dims[0] + y * (vtkIdType)dims[0] + x;
scalars[idx] = airValue;
}
continue;
}
int px = qBound(0, (int)(u * (maskW - 1)), maskW - 1);
int py = qBound(0, (int)((1.0 - v) * (maskH - 1)), maskH - 1); // Y翻转
uchar maskVal = maskBits[py * maskBpl + px];
bool inMask = (maskVal > 127);
bool shouldCut = cutInside ? inMask : !inMask;
if (shouldCut) {
vtkIdType idx = z * (vtkIdType)dims[1] * dims[0]
+ y * (vtkIdType)dims[0] + x;
scalars[idx] = airValue;
}
}
}
});
volume->Modified();
qDebug() << "VolumeCutter " << timer.elapsed() << "ms";
}
3.3 GPU¶
GPU 实现逻辑与 CPU 完全一致,只是执行位置从三重循环换成 compute shader 并行。每个 invocation 对应一个体素,完成 world 计算、裁剪平面判断、MVP 投影和 mask 采样,然后直接在 SSBO 中修改体素值。
并行度天然由 GPU 提供,整体结构和 CPU 版本几乎一致,只是执行位置从多线程 for 循环换成了大规模并行计算。需要注意的是,如果计算完成后再把数据读回 CPU,会受到带宽影响,真正高效的方式是让体数据始终留在 GPU 上,直接参与后续体渲染流程。
#version 430 core
layout(local_size_x = 16, local_size_y = 8, local_size_z = 4) in;
layout(std430, binding = 0) buffer VolumeBuffer
{
int data[];
}
uVolume;
layout(binding = 0) uniform sampler2D uMask;
uniform mat4 uMVP;
uniform ivec3 uDims;
uniform vec3 uOrigin;
uniform vec3 uSpacing;
uniform int uCutInside;
uniform int uAirValue;
uniform vec4 uClipPlanes[6];
void main()
{
ivec3 gid = ivec3(gl_GlobalInvocationID);
if (any(greaterThanEqual(gid, uDims))) {
return;
}
int voxelIndex = gid.z * uDims.y * uDims.x + gid.y * uDims.x + gid.x;
vec3 world = uOrigin + vec3(gid) * uSpacing;
bool clipped = false;
for (int i = 0; i < 6; ++i) {
if (dot(uClipPlanes[i].xyz, world) + uClipPlanes[i].w > 0.0) {
clipped = true;
break;
}
}
if (clipped) {
return;
}
vec4 clip = uMVP * vec4(world, 1.0);
if (abs(clip.w) < 1e-7) {
return;
}
vec2 uv = (clip.xy / clip.w) * 0.5 + 0.5;
if (any(lessThan(uv, vec2(0.0))) || any(greaterThan(uv, vec2(1.0)))) {
if (uCutInside == 0) {
uVolume.data[voxelIndex] = uAirValue;
}
return;
}
ivec2 maskSize = textureSize(uMask, 0);
ivec2 maskCoord = ivec2(
int(uv.x * float(maskSize.x - 1)),
int((1.0 - uv.y) * float(maskSize.y - 1))
);
maskCoord = clamp(maskCoord, ivec2(0), maskSize - 1);
float maskVal = texelFetch(uMask, maskCoord, 0).r;
bool inMask = (maskVal > 0.5);
if ((uCutInside == 1) == inMask) {
uVolume.data[voxelIndex] = uAirValue;
}
}